




The anatomy of a link - What makes a good (and bad) link

Not all links are created equal.
One part of the Google algorithm is the number of links pointing at your website, but it
would be foolish to make this a raw number and not take into account the quality of
those links. Otherwise, it would just be a free for all, and everyone would be trying to
get as many links as they can with no regard for the quality of those links.
As mentioned earlier, back in the early days of search engine optimization, it pretty
much was a free for all because the search engines were not as good at determining the
quality of a link. As search engines have become more advanced, they have been able to
expand the link-related signals they can use beyond raw numbers.
Search engines can look at a number of factors in combination to give them an indicator
of quality. More to the point, search engines can attempt to understand whether the
link is likely to be a genuine, editorially-given link, or a spammy link. These factors
are outlined in more detail below.
There is something important to remember here, though: it isn’t really the link itself
you care about (to a certain degree). It is the page and the domain you are getting the
link from which we care about right now. Once we know what these factors are, it helps
set the scene for the types of links you should (and shouldn’t) be getting for your own
website.
Before diving into the finer details of links and linking pages, let’s look more broadly
at what makes a good link. To me, there are three broad elements of a link:
- Trust
- Diversity
- Relevance
If you can get a link that ticks off all three of these, you’re onto a winner! You
shouldn’t obsess over doing so, but you should always have it in the back of your
mind.
Links that are trusted
In an ideal world, all links that you get would be from trusted websites. By trust, we
mean what Google thinks of a website, and some will also refer to this as authority. As
we’ve discussed, Google came up with PageRank as a way to objectively measure the trust
of every single link they find on the web. Generally, the more PageRank a page has, the
more trusted it is by Google, the more likely it is to rank and the more likely it is to
help you rank better if it links to you. At a very basic level, the PageRank score of a given page will determine how well it ranks.
Whilst we are talking about trust, it is worth touching upon another topic and phrase that you may have heard of or may come across: TrustRank.
TrustRank differs from PageRank in that it was designed to help detect web spam as opposed to helping "score" webpages on the trust they held.
This is taken from the TrustRank paper, written in 2004:
Let us discuss the difference between PageRank and TrustRank first. Remember, the PageRank algorithm does not incorporate any knowledge about the quality of a site, nor does it explicitly penalize badness. In fact, we will see that it is not very uncommon that some site created by a skilled spammer receives high PageRank score. In contrast, our TrustRank is meant to differentiate good and bad sites: we expect that spam sites were not assigned high TrustRank scores.
If you click through to this PDF to read the full paper on TrustRank, you’ll notice that it is a joint effort between Stanford and Yahoo. There was some confusion as to who came up with the original idea for TrustRank because of this. Also, a patent granted to Google in 2009 referring to “Trust Rank” describes a very different process to the one in the original paper from 2004.
For now, we’re going to briefly discuss the idea of TrustRank from 2004 and how it may be used by the search engines to calculate trust. Note the word "may" - just because a patent is granted, it doesn't mean that the concepts within it are used and even if they are, we don't know when or to what extent they are used. At the same time, it's useful to look at because in the context of link building, it's useful to know how search engines could determine which pages on the web are spam or not.
Let’s start with this simple diagram:
![]()
Starting from the left side, if you imagine that you have a list of websites you trust
100 percent, it may include sites like the BBC, CNN, The New York Times, etc. In this
“seed list” you have no spam whatsoever because these are super high-quality websites
with high level of editorial control.
As we move one step to the right, we first have a list of websites that are one link away
from the trusted seed set. The amount of spam increases ever so slightly but not a
lot.
Now go to the far right of the diagram, and we can see that, even if a list of websites
is just three links away from the trusted seed set, websites in that list are more
likely to be spam – as many as 14 percent of them, in fact.
Therefore, the search engines could define their own trusted seed set of websites and use
this as a starting point for crawling the web. As they crawl through these websites and
follow the external links, they can see how far away any given website is from the
trusted seed set. The implication being that the further away from there a website is
the higher likelihood it has to be spam.
While this isn’t an exact science, when you think of the billions of pages online which
need to be measured for trust, this is a highly scalable way of doing it, and the tests
from the original paper showed that it worked well, too.
Remember, we don’t know to what extent this is actually used by the search engines, and remember that it was a Yahoo! Patent. But as a mental model, it’s one way to think about how
trust could be inferred by using the structure of the web and a trusted seed set of
websites.
Links that are diverse
There are two types of diversity that I want to cover here:
- Diversity of linking domains
- Diversity of link type
Both of these are important if we want to build good links and have a strong, robust link
profile.
Diversity of linking domains
Diversity of linking domains simply means getting links from lots of different domains –
not the same ones over and over again. Take your mind back to earlier when we talked
about asking for a recommendation for a plumber. If five different friends who don’t
know each other all recommend the same plumber, that’s a pretty good sign that they are
good!
Taking it back online, if you have 100 links but they only come from 5 domains, that
isn’t as strong a signal as 100 links from 100 domains.
Diversity of link type
Diversity of link type means getting links from different types of domains. A natural
link profile will have links from blogs, forums, newspapers, old sites, new sites – you
get the idea.
Links that are relevant
The word relevant is not referring to the page that the link is on, but rather it is referring to the link itself. As we discussed earlier, anchor text allowed Google to discover the possible topic of a page without even having to crawl it, and it became a strong signal to them.
Therefore we need to acquire links to our website that are relevant to us. We can do this by trying to make the anchor text contain a keyword that we are targeting and is relevant to us. However, caution is needed here in light of the Google Penguin updates which were believed to partly target the over-optimization of anchor text via keyword usage.
Every website that wants to rank well for their target keywords, especially in competitive industries, needs relevant links. It is all about balance. You can’t overdo any one type of link building or make it obvious to search engines what you’re doing.
Elements of a page that may affect the quality of
a link
As discussed in previous sections, Google does not simply look at the raw number of links pointing at your website. They look at many other factors to try and assess the quality of a link and how much value it should pass to the target page. So what are these factors and what does it mean for your link building work?
Some of these factors are mentioned in a patent filed by Google in 2004 and granted in 2010, which became known as the “reasonable surfer” model. It basically outlines how various elements of a link, as well as the page containing the link, may affect how Google treats a link.
Let’s explore how these may affect your work and what you need to remember about each of them.
Number of other outbound links on a page
If the link pointing to your website is among hundreds or thousands of other outbound links on a single page, then chances are that it isn’t as valuable as when it's amongst a much smaller number. If you think about it from a user’s point of view, they probably are not going to find a page with hundreds of links particularly useful. While there are exceptions, on the whole, these types of pages do not provide a good user experience.
Also, going back to how PageRank works, the higher the number of outbound links on a page there are, the less value each of those links is worth. This isn’t a hard and fast rule, though, and has been the topic of hot debate in the SEO industry for many years, particularly in relation to PageRank sculpting.
How this affects your work
When seeking to get links from existing pages on a website, as opposed to new pages, look at the number of other outgoing links on a page using a tool such as Check My Links. If the number looks high, then you may want to consider whether the link is worth going for and spending time acquiring. Obviously you should take account of other factors, too, such as whether the domain is a particularly strong one to get a link from, even if it is among hundreds of other links. It could also be a super relevant link in terms of the topic of the page when compared to your website, which may offset the high volume of links and mean that there is value for you.
You may also want to consider whether there is a genuine reason for a high number of other links on the page. If there is a genuine reason, then the link may still be worth going for.
One thing you should definitely look out for is a lot of links to other websites which are not related to the topic of your page. In particular, look for links which look like they go to gambling, poker, pills, and health websites. If you see these, then you may be looking at a link exchange page where the webmaster has only put those links in place because they got one back from the site being linked to. These are the type of reciprocal links that Google does not like to see and will probably reduce the value of.
The quality of other websites being linked to from that
page
Leading on from the previous section, there is the concept of being within a “bad neighborhood” when it comes to your link profile. This stems from the idea that if you are seen to be clustered and associated with a load of other low-quality websites, your website could be assumed to be the same kind of quality.
One way to get into a bad neighborhood is to get links from the same places as low-quality, spammy websites. So if your website is linked to from the same page as 25 other websites, most of which are low quality, it isn’t a good signal to send to Google.
This ties in with your analysis of the number of outgoing links on a page. Quite often, you will find that pages with high numbers of outgoing links will have lower editorial standards. This naturally means that they are more likely to be linking to lower quality websites.
You definitely want to avoid instances of your website getting links from the same pages as low-quality websites. This helps Google see that you are a genuine website that doesn’t partake in any low-quality link building.
If you find one or two instances of getting low-quality links, then you probably will not have any issues. But if you find that many of your links are coming from low-quality pages and bad neighborhoods, then you will want to take a closer look and see if these links are ones that could be adding value or not.
How this affects your work
It can be hard to investigate the quality of every website being linked to from a page you are considering as a link target. You could do some scraping and assess the quality of outgoing links using some metrics, but doing this on scale can be quite intensive and take a lot of time.
You need to develop a gut feeling and instincts for link building. Many experienced link builders will be able to look at a page and know right away if the outgoing links are to low-quality websites. This gut feeling only comes with time and practice.
Personally, if I look at a page of links and it looks like a link exchange page that doesn’t appeal to me as a user, it probably isn’t a high quality page. I’d also look for lots of exact match keyword links to other websites which is a telltale sign of low editorial standards.
The page has a penalty or filter applied
This one is a bit controversial. Traditionally, the official line from Google has always been that links from bad pages can’t hurt you. There have been a few comments from Google employees to the contrary, but, on the whole, their stance has always been the same. However, we have seen this stance downplayed a little in recent years with various comments from Googlers becoming a lot softer and not explicitly saying that links from bad pages can’t hurt you. My own personal experience (and that of many SEO professionals) is that links from bad pages or penalized pages can hurt you and early iterations of Google Penguin reduced the rankings of many websites that had low-quality links pointing at them.
I can see why Google hold this public stance. They do not want to encourage people to deliberately point bad links at their competitors in an effort to hurt their rankings. Of course Google also introduced the disavow tool which allows a webmaster to tell them about links which they feel are low quality and not wanted when it comes to the link graph.
Every SEO should be aware of this practice and know how to deal with. We will go into more detail on identifying and removing link-based penalties later, but for now, we will stick within the context of this chapter.
How this affects your work
You need to be able to identify links from pages which may be low quality in the eyes of Google. You also need to be able to spot low-quality pages when identifying possible link targets. Later in this book, we will explore a method for identifying large numbers of low-quality links in a link profile. For the moment, it really comes down to your own instincts and the way you surf the web. You will have your own gut feeling when you open a page and will know instinctively whether to trust it and whether it’s relevant or not. Ultimately, this is one of the best ways to judge the value of a page because you’re using your human instincts.
Number of incoming links to the page
If the page you are getting a link from has lots of other links pointing at it, then that gives the page a level of authority that is then passed onto your website via PageRank. Chances are that, if the page is a genuinely good resource, then it will accrue links over time which will give it a level of link equity that many spammy pages will never get. Therefore, a link from a page with lots of link equity is going to be far more valuable to you.
At the same time, if this page is a genuinely good resource, the editorial standards will be a lot higher, and you’ll have a tougher time getting your link placed. This is actually a good thing: the harder a link is to get, the higher the value that link usually is.
How this affects your work
When you are looking at a page as a possible link target, take a quick look at a few metrics to get a feel for how strong that page is and how many links it has. By far, the quickest way to do this is to have a few extensions or plugins added to your browser that can instantly give you some info. For example if you have the MozBar installed, you can get a quick measure of the Page Authority and the number of links Moz has discovered pointing to that page.
Age of the domain
With age can come authority, as long as the website is of high quality. Also, if you get a link from a new domain, naturally that domain will not be as strong because it has not had time to get many links. Don’t get too caught up here though, the age of the domain itself isn’t what you’re looking at directly here, rather, it’s the implication that with an older domain may come more links and authority.
Because of this, I wouldn’t recommend using the age of a domain as a hard and fast metric. Instead, you could use domain age is as a way to filter a huge set of possible link targets. For example, you could filter link targets to only show you ones which are more than two years old which may give you a slightly higher-quality set of results.
How this affects your work
You can’t affect the age of a domain, so don’t worry too much about it. You can use domain age as a way to filter large sets of link targets, but there are many other better metrics to use.
Link from within a PDF
Within a PDF file, you can link out to external websites, much in the same way you can on a normal webpage. If this PDF is accessible on the web, the search engines are capable of crawling it and finding the links.
How this affects your work
In most cases, your day-to-day work probably won’t be affected that much, given that many link building techniques involve standard links on webpages. But if you work in an industry where PDFs are regularly created and distributed in some form (e.g., whitepapers), you should take the time to make sure you include links and that they point to the right pages.
In this case, you can also take advantage of various websites that offer submission of PDFs or whitepapers to get more links. This can work well because some of these sites may not usually link to you from a standard webpage.
The page being crawlable by the search engines
This is a big one, if the search engines never find the page where your link is placed, it will never count. This is usually not a problem, but it is something you should be aware of.
The main way a page can be blocked is by using a robots.txt file, so you should get into the habit of checking that pages are crawlable by the search engines. You can use this simple JavaScript bookmarklet to test if a
page is blocked in robots.txt.
There are other ways that a page may be blocked from search engines and therefore they may not discover your links. For example, if a page has elements such as JavaScript, Flash, or AJAX, it is possible that search engines may not be able to crawl those elements. If your link is inside one of these elements, it may never be discovered and counted.
In general, the search engines are getting much better at discovering links and content within these elements. However, it is something to keep an eye on when you’re getting links.
One way to see if a page has been crawled and indexed by Google is to check whether a page is cached or not, you can simply type “cache:” before the URL and put it into the Google Chrome address bar. If the page is cached, you will see a copy of it. If it isn’t cached, you will see something like this:

Elements of a link that affect its quality
We must also consider which elements of a link itself the search engines can use to assess its quality and relevance. They can then decide how much link equity (and other signals such as relevance) to pass across that link.
Again, many of these elements are part of the “reasonable surfer” model and may include things such as:
- The position of the link on the page (e.g., in the body, footer, sidebar, etc.)
- Font size / color of the link
- If the link is within a list, and the position within that list
- If the link is text or an image, if it is an image, how big that image is
- Number of words used as the anchor text
We’ll look at more of these elements later.
For now, here’s the basic anatomy of a link:
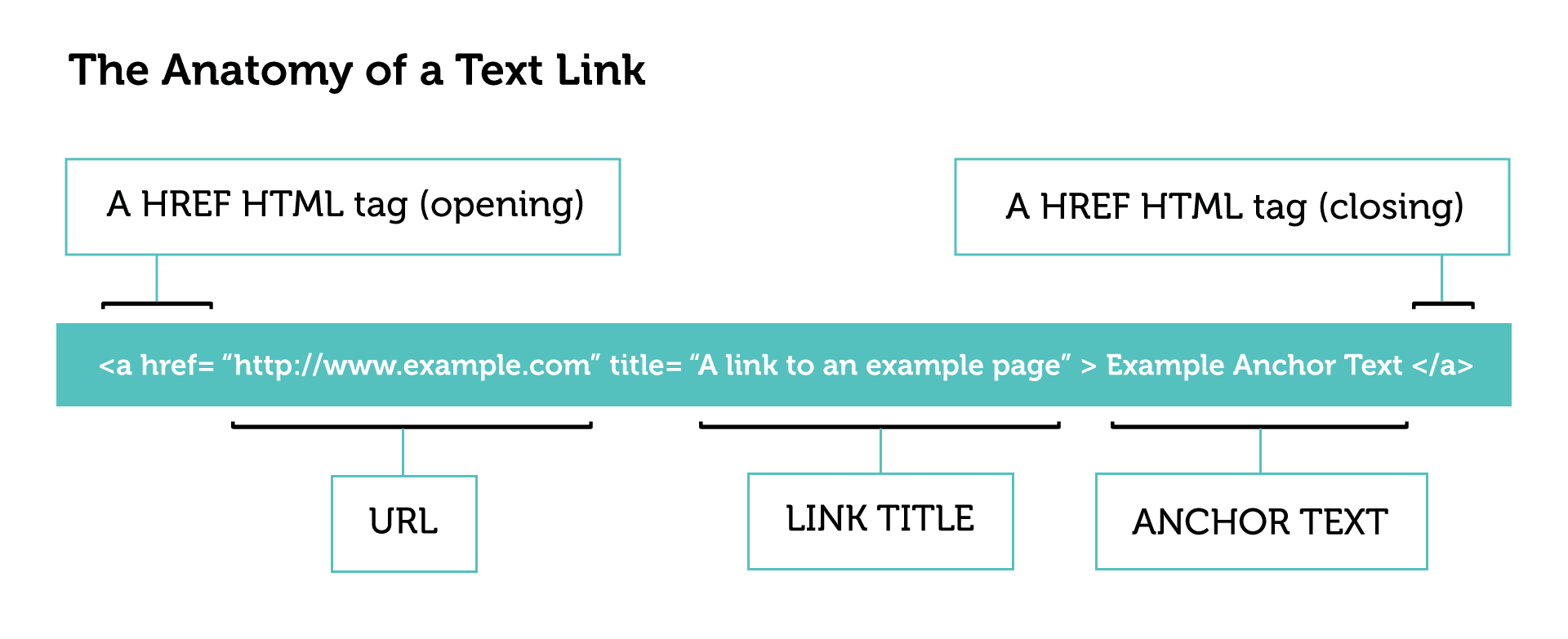
URL
The most important part of a link is the URL that is contained within it. If the URL is one that points to a page on your website, then you’ve built a link. At first glance, you may not realize that the URL can affect the quality and trust that Google put into that link, but it can have quite a big effect.
For example if the link is pointing to a URL that is one of the following:
- Goes through lots of redirects (or just one)
- Is blocked to search engine crawlers by a robots.txt file
- Is a spammy page (e.g., keyword-stuffed, sells links, machine-generated)
- Contains viruses or malware
- Contains characters that Google can’t / won’t crawl
- Contains extra tracking parameters at the end of the URL
All of these things can alter the way that Google handles that link. It could choose not to follow the link or it could follow the link, but choose not to pass any PageRank across it.
In extreme cases, such as linking to spammy pages or malware, Google may even choose to penalize the page containing the link to protect its users. Google does not want its users to visit pages that link to spam and malware, so it may decide to take those pages out of its index or make them hard to find.
How this affects your work
In general, you probably don’t need to worry too much on a daily basis about this stuff, but it is certainly something you need to be aware of. For example, you really need to make sure that any page you link to from your own site is good quality. This is common sense, really, but SEO professionals tend to take it a lot more seriously when they realize that they could receive a penalty if they don’t pay attention!
In terms of getting links, you can do a few things to make your links as clean as possible:
- Avoid getting links to pages that redirect to others. Certainly avoid linking to a page that has a 302 redirect because Google does not tend to pass PageRank across these
- Avoid linking to pages that have tracking parameters on the end. Sometimes Google will index two copies of the same page and the link equity will be split. If you absolutely can’t avoid doing this, then you can use a rel=canonical tag to tell Google which URL is the canonical so that they pass the link equity across to that version
Position of the link of a page
As a user, you are probably more likely to click on links in the middle of the page that in the footer. Google understands this and in 2004 it filed a patent, which was covered well by Bill Slawski. The patent outlined the “reasonable surfer” model, which included the following:
Systems and methods consistent with the principles of the invention may provide a reasonable surfer model that indicates that when a surfer accesses a document with a set of links, the surfer will follow some of the links with higher probability than others.
This reasonable surfer model reflects the fact that not all of the links associated with a document are equally likely to be followed. Examples of unlikely followed links may include “Terms of Service” links, banner advertisements, and links unrelated to the document.
The following diagram, courtesy of Moz, helps explain this a bit more:
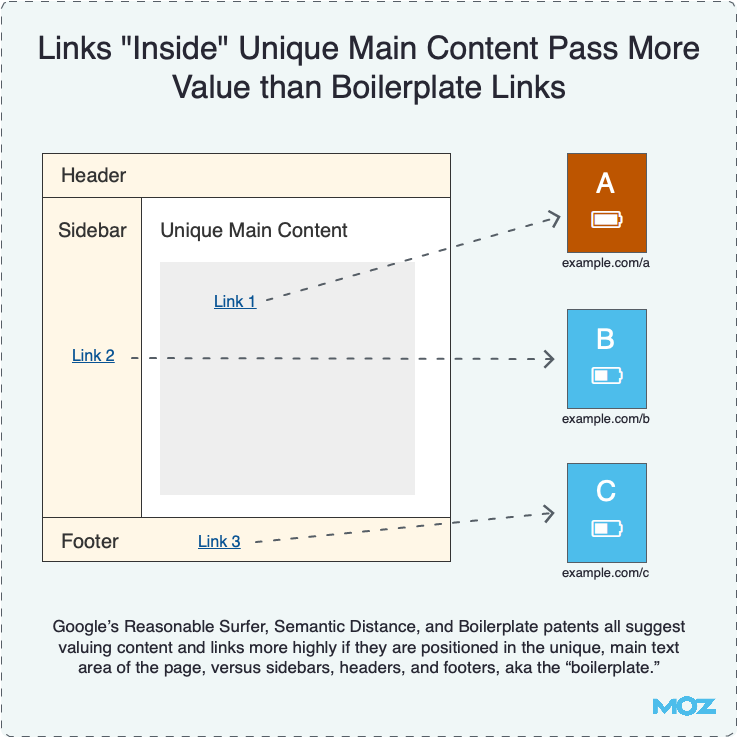
With crawling technology improving, the search engines are able to find the position of a link on a page as a user would see it and, therefore, treat it appropriately.
If you’re a blogger and you want to share a really good resource with your users, you are unlikely to put the link in the footer, where few readers will actually see it. Instead, you’re likely to place it front and center of your blog so that as many people see it and click on as possible.
Now compare this to a link in your footer to your privacy policy page. It seems a little unfair to pass the same amount of link equity to both pages, right? You’d want to pass more to the genuinely good resource rather than a standard page that users may not actually read.
Anchor text
For SEO professionals, this is probably second in importance to the URL, particularly as Google put so much weight on it as a ranking signal, even today where, arguably, it isn’t as strong a signal as it used to be.
Historically, SEOs have worked very hard to make anchor text of incoming links the same as the keywords which they want to rank for in the organic search results. So, if you wanted to rank for “car insurance” you’d try to get a link that has “car insurance” as the anchor text.
However, after the rollout of the Penguin update on April 2012, SEOs started taking a more cautious approach to anchor text. Many SEO pros reported that a high proportion of unnatural anchor text in a link profile led to a drop in organic traffic after the Penguin update was released.
The truth is that the average blogger, webmaster, or Internet user will NOT link to you using your exact match keywords. It’s even less likely that lots of them will! Google finally picked up on this trick and hit websites that over-optimized their anchor text targeting.
Ultimately, you want the anchor text in your link profile to be a varied mix of words. Some of it keyword-focused, some of it focused on the brand, and some of it not focused on anything at all. This helps reduce the chance of you being put on Google’s radar for having unnatural links. The truth is that a lot of the time, you also can’t control this and it’s therefore something you shouldn’t worry too much about.
Nofollowed / UGC / Sponsored link attributes vs. Followed Links
The nofollow attribute, in the context of link profile analysis, will be discussed a little later. For now, here are some of the basics you need to know.
The nofollow attribute was adopted in 2005 by Yahoo, Google, and MSN (now Bing). It was intended to tell the search engines when a webmaster didn’t trust the website they were linking to. It was also intended to be a way of declaring paid links (i.e., advertising).
In terms of the quality of a link, if the nofollow attribute is applied, it shouldn’t pass any PageRank. This effectively means that nofollow links are not counted by Google as part of their link graph and shouldn’t make any difference when it comes to organic search results.
Over the years, the nofollow attribute has developed and can be used in a variety of situations. In 2019, Google introduced two new attributes designed to allow for more granularity and flexibility for webmasters to mark their links in certain ways. They also confirmed that they may change how they decide to interpret all three attributes and implied that in some cases, they may count links as part of their link graph.
This confirmed something that some SEOs had long suspected, that Google may selectively decide when to pass link equity across a nofollow link or not.
In terms of your work, when building links, you should always try to get links that are followed, which means they should help you with ranking better. Having said that, having a few nofollow links in your profile is natural and sometimes, can't be helped and as mentioned above, may actually help.
You should also think of the other benefit of a link – traffic. If a link is nofollow, but get lots of targeted traffic through it, then it is worth building. There can also be a secondary benefit to nofollow links in that if you get a nofollow link from a high-quality website which has lots of traffic, you may get other links from people who see it and also link to you from their own websites. This happens quite a lot with top-tier newspaper websites where it is quite common to use the nofollow attribute, but getting one from them could lead to other publications linking to you as well and some of these may be followed.
Link title
Check out this page for some examples and explanations of the link title attribute.
The intention here is to help provide more context about the link, particularly for accessibility, as it provides people with more information if they need it. If you hover over a link without clicking it, most modern browsers should display the link title, much in the same way they’d show the ALT text of an image. Note that the link title is not meant to be a duplication of anchor text; it is an aid to help describe the link.
In terms of SEO, the link title doesn’t appear to carry much weight for ranking. In fact, Google appeared to confirm that they do not use it at PubCon in 2005, according to this forum thread. My testing has confirmed this as well.
Text link vs. Image link
This section so far has been discussing text-based links, by that we mean a link that has anchor text containing standard letters or numbers. It is also possible to get links directly from images, the HTML for this look slightly different:

Notice the addition of the img src attribute, which contains the image itself. Also note how there is no anchor text as we’d usually find with a text link. Instead, the ALT text (in this example, the words “Example Alt Text”) is used instead.
My limited testing on this has shown that the ALT text acts in a similar way to anchor text but doesn’t appear to be as powerful.
Link contained within JavaScript / AJAX / Flash
In the past, the search engines have struggled with crawling certain web technologies such as JavaScript, Flash and AJAX. They simply didn’t have the resources or technology to crawl through these relatively advanced pieces of code. These pieces of code were mainly designed for users with full browsers which were capable of rendering them.
For a single user who can interact with a webpage, it is pretty straightforward for them to execute things like JavaScript and Flash. However, a search engine crawler isn’t like a standard web browser and doesn’t interact with a page the way a user does.
This meant that if a link to your website was contained within a piece of JavaScript code, it was possible that the search engines would never see it – therefore your link would not be counted. Believe it or not, this actually used to be a good way of intentionally stopping search engines from crawling certain links.
However, the search engines and the technology they use has developed quite a bit and they are now, at least, more capable of understanding things like JavaScript. They can sometimes execute it and find what happens next, such as links and content being loaded.
In May 2014, Google published a blog post explicitly stating that they were trying harder to get better at understanding websites that used JavaScript. They also released a new feature, fetch and render, in Google Webmaster Tools (now called the Search Console) so that we could better see when Google has problems with JavaScript.
More recently in 2017, Google has updated their guidelines on the use of Ajax and have been pretty explicit about its ability to correctly understand JavaScript. It’s clear that they still have a long way to go, but are much better than ever at understanding JavaScript.
But this doesn’t mean we don’t have to worry about things. You still must make links as clean as possible and make it easy for search engines to find your links. This means building them in simple HTML whenever possible.
How this affects your work
You should also know how to check if a search engine can find your link. This is pretty straightforward. Here are a few methods:
Text surrounding the link
There was some hot debate around this topic toward the end of 2012, mainly fueled by this Whiteboard Friday on Moz, where Rand Fishkin predicted that anchor text, as a signal, would become weaker. In the video, Fishkin gave a number of examples of what appeared to be strange rankings for certain websites that didn’t have any exact match anchor text for the keyword being searched. In Fishkin’s opinion, a possible reason for this could be co-occurrence of related keywords which are used by Google as another signal.
It was followed by a post by Bill Slawski, which gave a number of alternative reasons why these apparently strange rankings may be happening. It was then followed by another great post by Joshua Giardino, which dove into the topic in a lot of detail. You should read both of these excellent posts.
Having said all of that, there is some belief that Google could certainly use the text surrounding a link to infer some relevance, particularly in cases when anchor text such as “click here” (which isn’t very descriptive) is used.
If you’re building links, you may not always have control of the anchor text, let alone the content surrounding it. But if you are, then think about how you can surround the link with related keywords and possibly tone down the use of exact keywords in the anchor text itself.
Don't have time to read the book now? Take it away with you in either a pdf or download our Kindle version

